0. Introduction
인간을 '천하무적(invincible)'으로 만들어주는 것이 바로 '언어(language)', 그리고 '글쓰기(writing)'는 인간이 발견한 지식을 전파하고 공동으로 작업할 수 있도록 해 줌.
meaning: Signifier(symbol) <=> Signified (idea or thing)
우리는 컴퓨터에서 어떻게 'meaning'을 사용할까? -> NLTK 사용해 볼 수 있음(기본적인 다양한 기능을 제공하지만, 뛰어나지는 않음).

WordNet의 한계
- 뉘앙스를 반영하지 못 함 ('good'과 'proficient'가 동의어로 나와있지만, 사실은 뉘앙스가 다르잖아)
- 신조어를 모름 (New words, slang words,.. )
- 의미들의 관계나 유사도를 계산하지 못 함(good : marvelous)
전통적인 NLP 모델 (2012 전까지 쓰이던)
Hotel, Motel 이라는 단어를 1과 0으로 나타냄 (one-hot vectors)
hotel = [ 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 ]
motel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 ]
이렇게 하면 벡터의 크기는 모든 단어들의 수가 됨 -> 아주 큰 벡터
그리고 비슷한 단어인데 벡터가 직교하여(orthogonal) 유사도를 측정하지 못 함(찾아보기)
대안으로..
우리는 Wordnet의 동의어 리스트를 가져다 쓸 수 있겠지만, Wordnet은 너무 불완전 해. (-)
대신 우리 스스로 word-similarity table을 만들 수 있겠지만, 이렇게 하면 너무 큰 행렬이 만들어짐. (-)
Distributional Sementics
단어의 '의미(meaning)'는 가까이 등장하는 단어들에 의해 정해진다.

Word Vectors ( = word embeddings = word representations)
더 작은 벡터이지만 더 밀도 있는(one-hot이 아닌 숫자들) 벡터로 단어의 의미를 표현!
vector space(아래) -> Dimension이 큰 vector는 시각화하기 어렵기 때문에 차원을 축소하여 나타냄.
워드 임베딩이 잘 된 상태라면, 단어의 유사도가 높을수록 가까이 묶여져서 보여짐 (임베딩 후 확인하는 용도로 봐도 좋음)

1. word2vec
word vectors를 학습하기 위한 프레임워크(framework)
Idea
• We have a large corpus (“body”) of text
• Every word in a fixed vocabulary is represented by a vector
• Go through each position t in the text, which has a center word c and context (“outside”) words o
• Use the similarity of the word vectors for c and o to calculate the probability of o given c (or vice versa)
• Keep adjusting the word vectors to maximize this probability


Center 단어와 주변 단어들 간의 사전확률을 다 곱하면 '유사도(likelihood)'
-> 여기서 확률이 하나라도 0이 나오면 Likelihood 전체가 0이 되어 최적화가 되지 않음. 그래서 log를 취해준다.
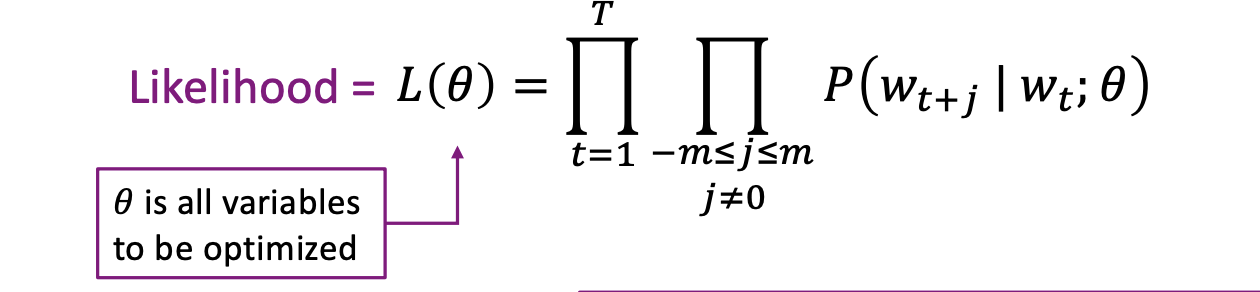
Likelihood를 평균내고(Scaling 목적), 로그를 붙여줌(확률의 곱이라서 값이 매우 작아진 상태이기 때문에 로그 취하는 게 효과적)
그리고 J(theta)값을 최소화 하는 theta를 찾아야 함 (Probability를 극대화하는)
이는, 컴퓨터는 보통 최소화 문제를 잘 풀기 때문!
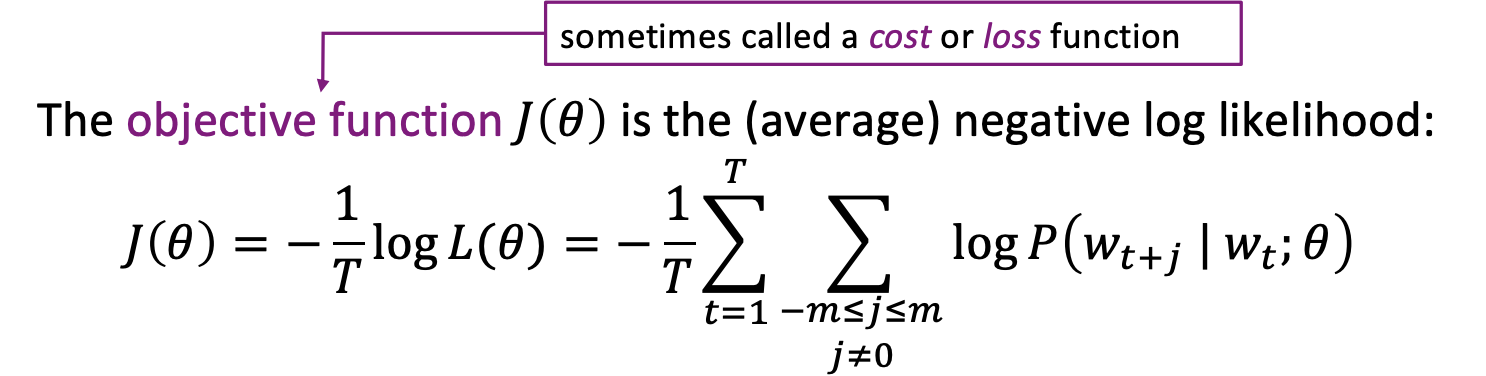
확률 계산하는 방법
Softmax 함수도 아래의 식과 같음.
max: exponential 함수를 통해서 큰 숫자는 더 크게 만듦
soft: 작은 숫자한테는 작은 확률을 부여함.
확률인데 음수가 나오면 안되니까 exponential 취해줌.
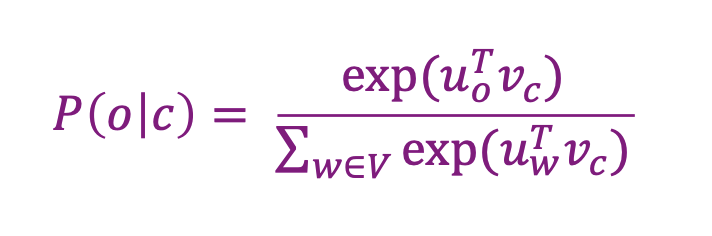



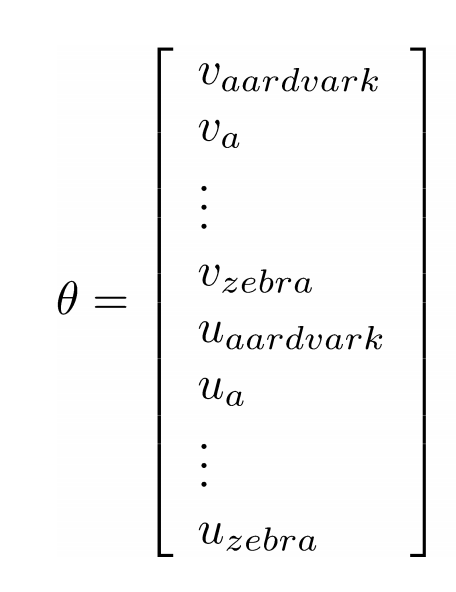
theta: 모든 모델 parameters를 하나의 벡터로 나타낸다. (d dimension, v개의 words)
u와 v는 처음엔 random vector로 시작하고, 이 값들을 optimization 과정에 넣을 것.
질문) theta는 어디에 곱해지는 거지??
답) theta안에 u와 v가 들어가 있는 거야! (중심단어인지 아닌지의 여부를 알아야하니까 u,v 따로 있는거고)
모든 단어들이 각각 중심 단어일 때와 주변 단어일 때로 나눠서 theta 벡터를 나타냄
(근데 이건 Andrew Ng교수님 강의랑 표기가 달라서 헷갈림 ㅜㅜ)
하지만 word2vec이 다의어/중의어 문제를 해결해주지는 못 함. 다른 모델을 사용해야 함. (ELMo 같은)
Cost Function과 Gradient Descent (아래 사진)
'Machine Learning and Deep Learning' 카테고리의 다른 글
| Pytorch - Introduction to PyTorch Tensors (0) | 2022.03.28 |
|---|---|
| Pytorch - Introduction to Pytorch (0) | 2022.03.27 |
| [Deep Learning] Sequence Models week4. Trans (0) | 2021.06.27 |
| [Deep Learning] Sequence Models week3. Bean Search, Bleu Score and Attention Model (0) | 2021.06.26 |
| [Deep Learning] Sequence Models week2-3. Sentiment Classification and Debiasing Word Embeddings (0) | 2021.06.21 |